K-Nearest Neighbor Algorithm
In pattern recognition, the k-nearest neighbors algorithm (k-NN) is a non-parametric method proposed by Thomas Cover used for classification and regression.
In both cases, the input consists of the k closest training examples in the feature space. The output depends on whether k-NN is used for classification or regression.
k-NN is a type of instance-based learning, or lazy learning, where the function is only approximated locally and all computation is deferred until function evaluation. Since this algorithm relies on distance for classification, normalizing the training data can improve its accuracy dramatically.
Both for classification and regression, a useful technique can be to assign weights to the contributions of the neighbors, so that the nearer neighbors contribute more to the average than the more distant ones. For example, a common weighting scheme consists in giving each neighbor a weight of 1/d, where d is the distance to the neighbor.
I worked on this system for 2 months trying to do a simulation of K-Nearest Neighbor.
Technologies:
- - Javascript
- - HTML
- - CSS
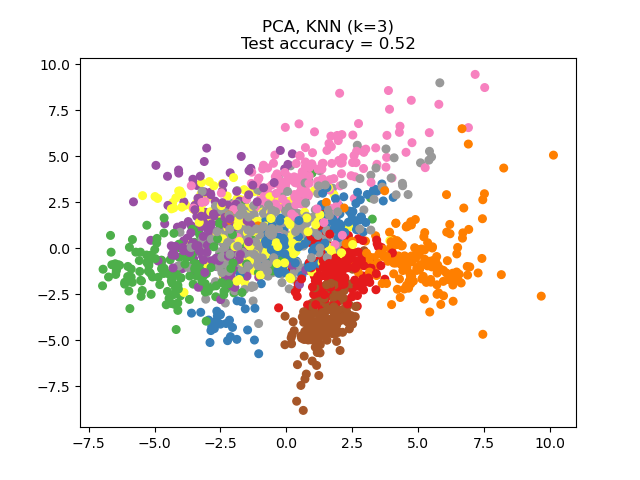
Results of the algorithm